This fourth post in our series about binary descriptors that will talk about the BRISK descriptor [1]. We had an introduction to patch descriptors, an introduction to binary descriptors and posts about the BRIEF [2] and the ORB [3] descriptors.
We’ll start by showing the following figure that shows an example of using BRISK to match between real world images with viewpoint change. Green lines are valid matches, red circles are detected keypoints.

BRISK descriptor – example of matching points using BRISK
As you may recall from the previous posts, a binary descriptor is composed out of three parts:
- A sampling pattern: where to sample points in the region around the descriptor.
- Orientation compensation: some mechanism to measure the orientation of the keypoint and rotate it to compensate for rotation changes.
- Sampling pairs: which pairs to compare when building the final descriptor.
Recall that to build the binary string representing a region around a keypoint we need to go over all the pairs and for each pair (p1, p2) – if the intensity at point p1 is greater than the intensity at point p2, we write 1 in the binary string and 0 otherwise.
The BRISK descriptor is different from the descriptors we talked about earlier, BRIEF and ORB, by having a hand-crafted sampling pattern. BRISK sampling pattern is composed out of concentric rings:

BRISK descriptor – BRISK sampling pattern
When considering each sampling point, we take a small patch around it and apply Gaussian smoothing. The red circle in the figure above illustrations the size of the standard deviation of the Gaussian filter applied to each sampling point.
Short and long distance pairs
When using this sampling pattern, we distinguish between short pairs and long pairs. Short pair are pairs of sampling points that their distance is below a certain threshold d_max and long pairs are pairs of sampling points that their distance is above a certain different threshold d_min, where d_min>d_max, so there are no short pairs that are also long pairs.
Long pairs are used in BRISK to determine orientation and short pairs are used for the intensity comparisons that build the descriptor, as in BRIEF and ORB. The
To illustrate this and help make things clear, here are figures of BRISK’s short pairs – each red line represent one pair. Each figure shows 100 pairs:

BRISK descriptor – BRISK short pairs

BRISK descriptor – BRISK short pairs

BRISK descriptor – BRISK’s short pairs

BRISK descriptor – BRISK’s short pairs
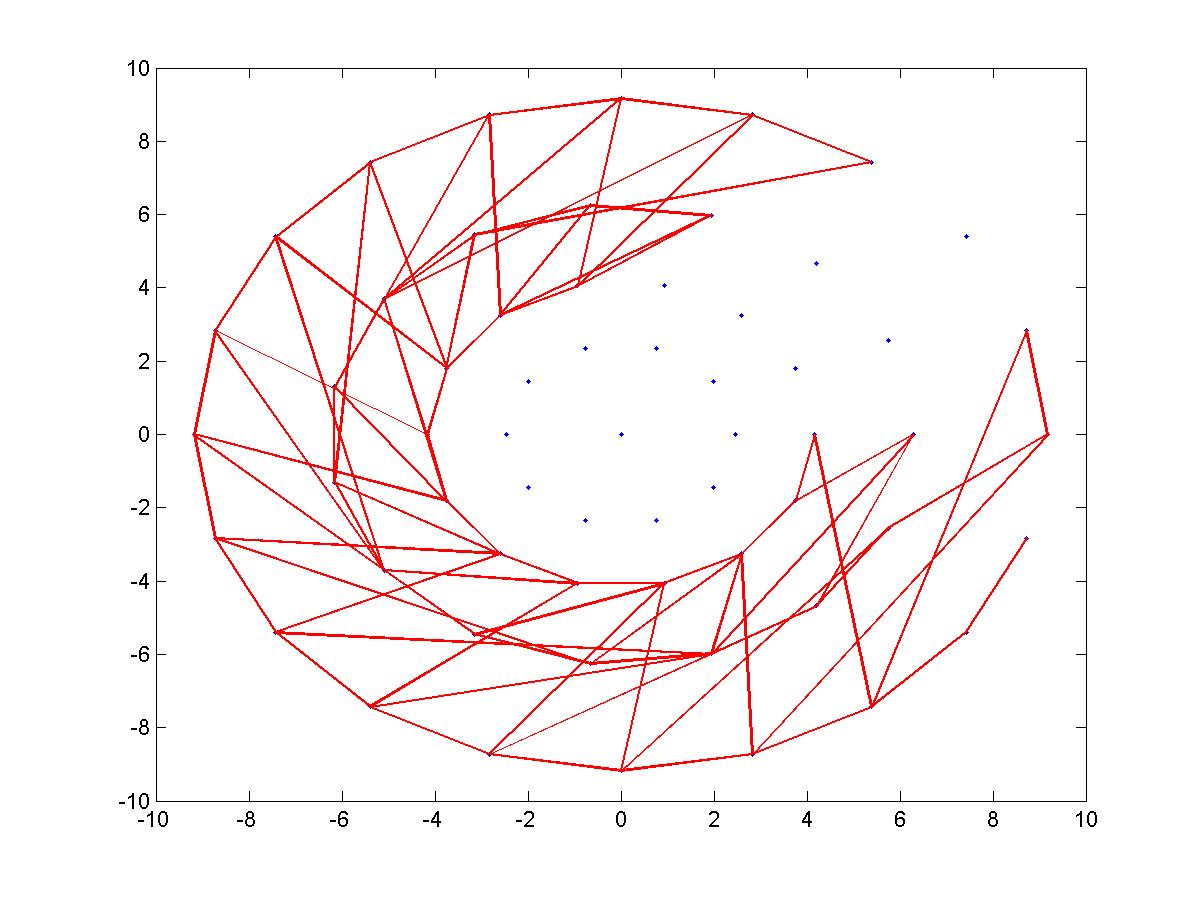
BRISK descriptor – BRISK’s short pairs
Computing orientation
BRISK is equipped with a mechanism for orientation compensation; by trying to estimate the orientation of the keypoint and rotation the sampling pattern by that orientation, BRISK becomes somewhat invariant to rotation.
For computing the orientation of the keypoint, BRISK uses local gradients between the sampling pairs which are defined by

BRISK descriptor – local gradients forumla
Where g(pi,pj) is the local gradient between the sampling pair (pi,pj), I is the smoothed intensity (by a Gaussian) in the corresponding sampling point by the appropriate standard deviation (see the figure above of BRISK sampling pattern).
To compute orientation, we sum up all the local gradients between all the long pairs and take arctan(gy/gx) – the arctangent of the the y component of the gradient divided by the x component of the gradient. This gives up the angle of the keypoint. Now, we only need to rotate the short pairs by that angle to help the descriptor become more invariant to rotation. Note that BRISK only use long pairs for computing orientation based on the assumption that local gradients cancel each other thus not necessary in the global gradient determination.
Building the descriptor and descriptor distance
As with all binary descriptors, building the descriptor is done by performing intensity comparisons. BRISK takes the set of short pairs, rotate the pairs by the orientation computed earlier and makes comparisons of the form:

BRISK descriptor – Intensity comparisons
Meaning that for each short pair it takes the smoothed intensity of the sampling points and checked whether the smoothed intensity of the first point in the pair is larger than that of the second point. If it does, then it writes 1 in the corresponding bit of the descriptor and otherwise 0. Remember that BRISK uses only the short pairs for building the descriptor.
As usual, the distance between two descriptors is defined as the number of different bits of the two descriptors, and can be easily computed as the sum of the XOR operator between them.
You probably ask what about performance. Well we’ll have a detailed post that will talk all about performance of the different binary descriptors, but for now I will say a few words comparing BRISK to the previous descriptors we talked about – BRIEF and ORB:
- BRIEF outperforms BRISK (and ORB) in photometric changes – blur, illumination changes and JPEG compression.
- BRISK slightly outperforms BRIEF in viewpoint changes, but performs about the same as ORB in overall.
Stay tuned for the next post in the series that will talk about the FREAK descriptor, the last binary descriptor we will focus on before giving a detailed performance evaluation.
Gil.
References:
[1] Leutenegger, Stefan, Margarita Chli, and Roland Y. Siegwart. “BRISK: Binary robust invariant scalable keypoints.” Computer Vision (ICCV), 2011 IEEE International Conference on. IEEE, 2011.
[2] Calonder, Michael, et al. “Brief: Binary robust independent elementary features.” Computer Vision–ECCV 2010. Springer Berlin Heidelberg, 2010. 778-792.
[3] Rublee, Ethan, et al. “ORB: an efficient alternative to SIFT or SURF.” Computer Vision (ICCV), 2011 IEEE International Conference on. IEEE, 2011.

Pingback: A tutorial on binary descriptors – part 5 – The FREAK descriptor | Gil's CV blog
Hello , THANKS for the lecture =)
I’m a newbie to binary features so I have a little confused regarding of sampling pattern points. First, how we going to decide the position of each sampling point which taken around the keypoint? From the figure provide, the number of sampling points are arrange in 1, 10, 14, 15 and 20 per circle, how it get this order? Beside, how many pairs we can get from 60 points? Is it N*(N-1)/2 = 1770 pairs?
Really hope can hear from you soon. Thank you very much!
Hi,
BRISK uses a hand-crafted pattern that is illustrated in one of the figures in the post. The spatial arrangement of the sampling points was hard crafted.
From 60 points we indeed have 1770 pairs, but for creating the descriptor we take only those pairs that their distance is lower than a threshold, resulting in 512 “short distance” pairs.
Please let me know if you have any further questions.
Gil
Hi,
thankks for your super explanation.
One question: how is scale invariance achieved in BRISK ?
Rolf
Hi Rolf,
Thanks for your interest in my blog.
BRISK obtains the scale of the keypoint from the detector. In the original paper, the proposed BRISK detector was used.
The BRISK detector computes the FAST score in scale-space pyramid and takes the scale which scored the best.
Please let me know if you have any other questions.
Gil
OMG! I just realize I forget to say thank you for your previous precious replied. It did help me a lots! Thank you very much!
It’s ok, no worries. You are welcome!
hello!!! great post!! had a small query.. what is the dimension of the BRISK descriptor?
Pingback: Adding rotation invariance to the BRIEF descriptor | Gil's CV blog
I find 1024 differences is satisfactory, rotation and scale invarience isnt required if you just want to hop descriptor to descriptor.
Hi,
I didn’t understand what exactly do you mean. Can you elaborate?
Thanks,
Gil
Pingback: Performance Evaluation of Binary Descriptor – Introducing the LATCH descriptor | Gil's CV blog
Hii..gr8 work.,very easy to understand .I am having a doubt like in MATLAB we have direct extractHOGFeature which gives us a feature vector directly for Input image,but for binary descriptor MATLAB has detectBRISKFeature which give us feature points only ,then how can we generate feature vecture out of detected interest points.
Hi,
Thank you for your interest in my blog.
For extracting BRISK descriptors in Matlab, you can use the function extractFeatures:
http://www.mathworks.com/help/vision/ref/extractfeatures.html
Best,
Gil
Hi, Did you ever test “detectBRISKFeatures” MATLAB function for rotated images? It seems that this function (MATLAB function) is not rotation invariant? Am I right?
Hi,
I never used the Matlab implementation of BRISK (or any other detectors or descriptors). I only experimented with OpenCV.
Best,
Gil
Can you provide me some tutorials on how to implement it using opencv python?
I never used it in python, only in C++.
But I found some examples here:
https://github.com/kobejohn/python_brisk_demo
Great post thank a lot.
I have one question https://gilscvblog.files.wordpress.com/2013/08/brisk2.png in this figure i we look at the red circle there size increases as moving away from keypoint region what is the reason behind that?
Thank you for your interest in my blog.
The reason for this is to capture more fine information in the area close to the center of the patch and more course information in the peripheral areas of the patch.
Pingback: Feature Descriptors – Deep Learning KEYSCORE
Hey, how does the BRISK feature detector work? Can you give a simple explanation?
“To compute orientation, we sum up all the local gradients between all the long pairs and take arctan(gy/gx)” – It may be no big deal or it may be implied, or maybe I am wrong but I think it should be “we sum them up and divide by the number of long pairs, i.e. we take the average and then take arctan()…”.